Tennis Grand Slam Visualization & Winning Tournament Prediction
Thu, Oct 21, 2021
4-minute read
The datasets in this blog post are about 4 Tennis Grand Slams and their winners across various decades since 1968 from TidyTuesday.
library(tidyverse)
library(tidytext)timeline <- read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2019/2019-04-09/grand_slam_timeline.csv")
grand_slams <- read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2019/2019-04-09/grand_slams.csv") %>%
mutate(grand_slam = str_replace(grand_slam, "_", " "),
grand_slam = str_to_title(grand_slam)) %>%
mutate(grand_slam = fct_recode(grand_slam, "US Open" = "Us Open"))
player_dob <- read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2019/2019-04-09/player_dob.csv") %>%
mutate(first_title_age = age/365) %>%
select(-age)Working on timeline tibble
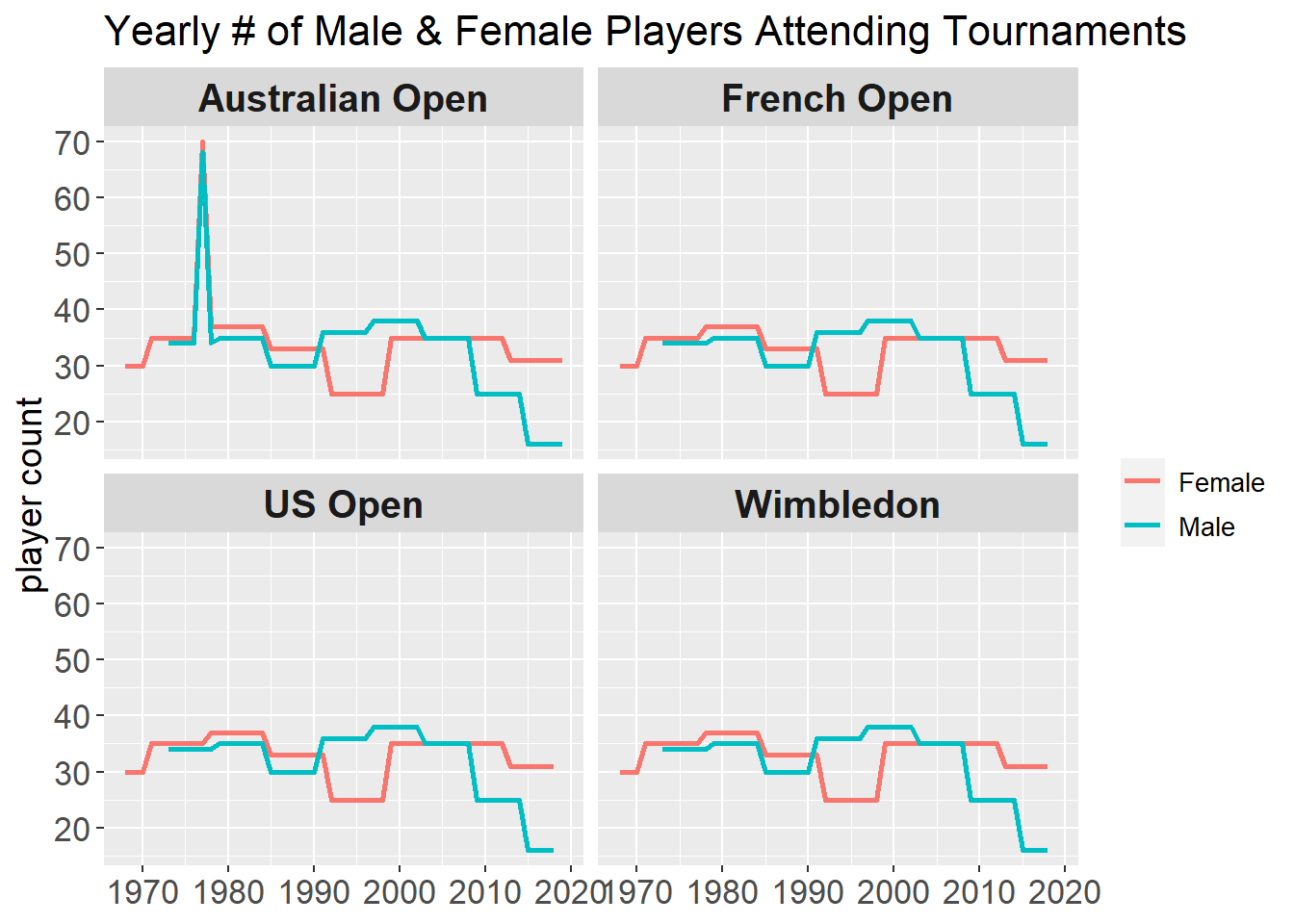
timeline %>%
count(year, tournament, gender, sort = T) %>%
ggplot(aes(year, n, color = gender)) +
geom_line(size = 1) +
facet_wrap(~tournament) +
labs(x = NULL,
y = "player count",
color = NULL,
title = "Yearly # of Male & Female Players Attending Tournaments") +
theme(
strip.text = element_text(size = 15, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 13),
legend.text = element_text(size = 10),
plot.title = element_text(size = 16)
)
timeline %>%
count(player, outcome, gender, sort = T) %>%
drop_na() %>%
filter(!str_detect(outcome, "Round|Qua")) %>%
group_by(outcome) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(player = reorder_within(player, n, outcome)) %>%
ggplot(aes(n, player, fill = gender)) +
geom_col() +
facet_wrap(~outcome, scales = "free_y") +
scale_y_reordered()+
labs(x = "count",
y = NULL,
fill = NULL,
title = "Top 10 Players in All Outcomes") +
theme(
strip.text = element_text(size = 15, face = "bold"),
axis.title = element_text(size = 14),
axis.text = element_text(size = 13),
legend.text = element_text(size = 10),
plot.title = element_text(size = 18)
)
Working on grand_slams&player_dob
Join two tibbles together.
joined_tbl <- grand_slams %>%
rename(tournament = "grand_slam") %>%
left_join(player_dob, by = "name") %>%
mutate(tournament_age = round(as.numeric(difftime(tournament_date ,date_of_birth))/365, 1),
first_title_age = round(first_title_age, 1)) %>%
mutate(grand_slam = if_else(str_detect(grand_slam, "Australian Open"), "Australian Open", grand_slam))
joined_tbl %>%
filter(rolling_win_count == 1) %>%
slice_min(first_title_age, n = 20) %>%
mutate(name = fct_reorder(name, first_title_age)) %>%
ggplot(aes(first_title_age, name, fill = grand_slam)) +
geom_col() +
geom_text(aes(label = year, color = grand_slam),nudge_x = 0.3, show.legend = F) +
labs(x = "first title age",
y = NULL,
fill = "tournament",
title = "The Youngest 20 Players Winning Grand Slam Title") 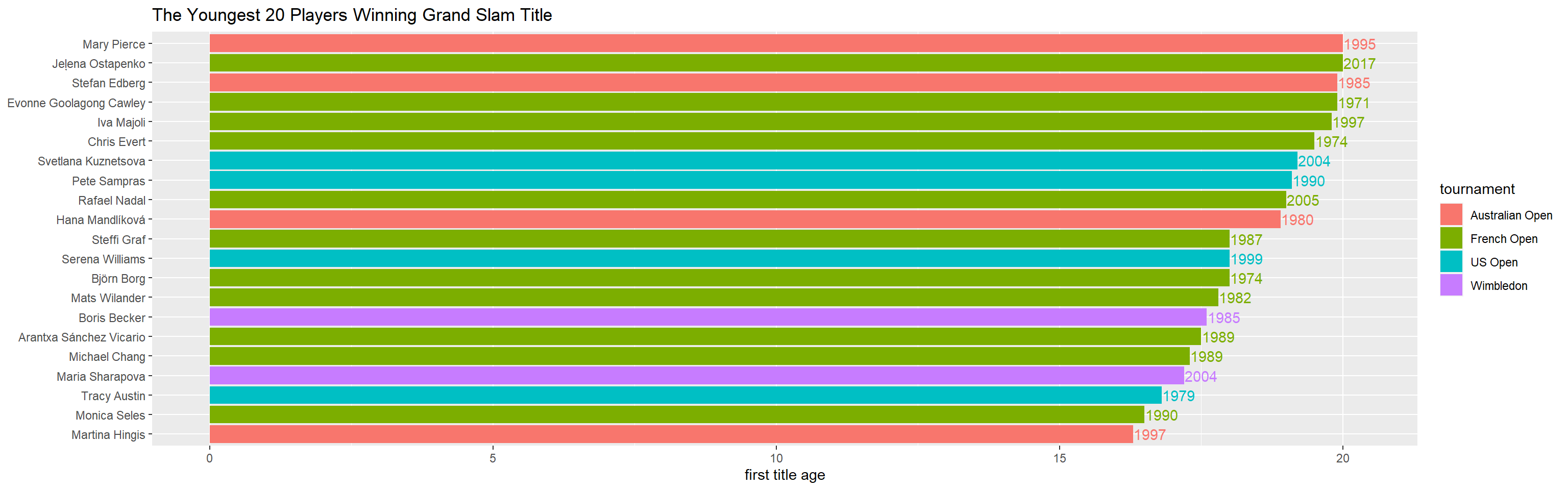
joined_tbl %>%
group_by(name) %>%
slice_max(rolling_win_count, n = 1) %>%
#filter(rolling_win_count > 5) %>%
ungroup() %>%
drop_na() %>%
mutate(name = reorder_within(name, rolling_win_count, gender)) %>%
ggplot(aes(rolling_win_count, name, fill = grand_slam)) +
geom_col() +
facet_wrap(~gender, scales = "free") +
scale_y_reordered() +
labs(x = "total win count",
y = "",
fill = "tournament")+
theme(
strip.text = element_text(size = 15, face = "bold"),
axis.title = element_text(size = 13),
axis.text = element_text(size = 11),
legend.text = element_text(size = 10),
plot.title = element_text(size = 18)
)
Predicting the winner of tournament
The following code is directly copied from David Robinson’s code with a few minor modifications. This is just for learning purposes, as this is my first time using a number of functions presented in the code.
dob <- player_dob %>%
select(player = name, date_of_birth)
tournaments <- grand_slams %>%
select(year, tournament = grand_slam, gender, tournament_date)
timeline_processed <- timeline %>%
inner_join(tournaments, by = c("year", "tournament", "gender")) %>%
arrange(player, tournament_date) %>%
filter(outcome != "Absent",
!str_detect(outcome, "Qualif")) %>%
group_by(player) %>%
mutate(rolling_play_count = row_number() - 1,
rolling_won_count = lag(cumsum(outcome == "Won"), default = 0),
rolling_finals_count = lag(cumsum(outcome %in% c("Won", "Finalist")), default = 0)) %>%
ungroup() %>%
filter(!(year == 1977 & tournament == "Australian Open")) %>%
mutate(won = outcome == "Won")
timeline_processed %>%
filter(outcome %in% c("Finalist", "Won")) %>%
arrange(tournament_date) %>%
group_by(rolling_won_count = pmin(rolling_won_count, 10)) %>%
summarize(pct_won = mean(won),
observations = n()) %>%
ggplot(aes(rolling_won_count, pct_won)) +
geom_line() +
expand_limits(y = 0)
Using dput() to save a lot of mundane typing!
match() is nifty here to create ranking.
outcome_rankings <- c("1st Round", "2nd Round", "3rd Round", "4th Round", "Quarterfinalist",
"Retired", "Semi-finalist", "Finalist", "Won")
tournament_scores <- timeline_processed %>%
filter(outcome %in% outcome_rankings) %>%
mutate(score_contribution = match(outcome, outcome_rankings)) %>%
group_by(player) %>%
mutate(previous_average = lag(cummean(score_contribution), default = 1)) %>%
ungroup() %>%
mutate(previous_performance = outcome_rankings[round(previous_average)],
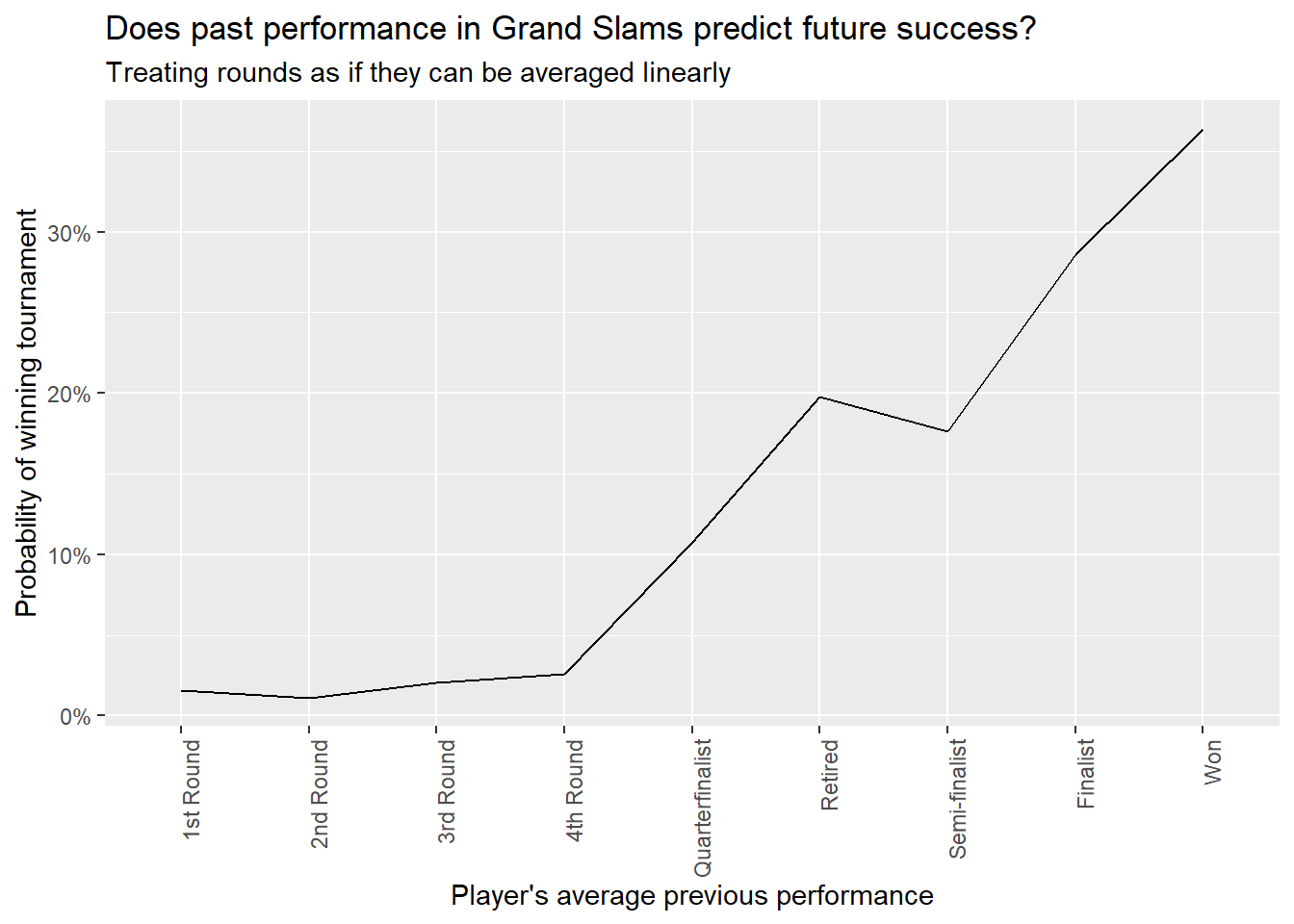
previous_performance = fct_relevel(previous_performance, outcome_rankings))tournament_scores %>%
group_by(previous_performance) %>%
summarize(observations = n(),
probability_win = mean(won)) %>%
ggplot(aes(previous_performance, probability_win, group = 1)) +
geom_line() +
scale_y_continuous(labels = scales::percent_format()) +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
labs(x = "Player's average previous performance",
y = "Probability of winning tournament",
title = "Does past performance in Grand Slams predict future success?",
subtitle = "Treating rounds as if they can be averaged linearly")