GDPR Data Visualization
Fri, Dec 17, 2021
4-minute read
This blog post analyzes the E.U.’s General Data Protection Regulation (GDPR) from TidyTuesday.
library(tidyverse)
library(tidytext)
library(lubridate)
library(scales)
theme_set(theme_bw())gdpr <- read_tsv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-04-21/gdpr_text.tsv")
gdpr_violations <- read_tsv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-04-21/gdpr_violations.tsv") %>%
mutate(article_violated = str_remove_all(article_violated, "\\s*"),
date = mdy(date))
gdpr## # A tibble: 425 x 7
## chapter chapter_title article article_title sub_article gdpr_text href
## <dbl> <chr> <dbl> <chr> <dbl> <chr> <chr>
## 1 1 General provi~ 1 Subject-matte~ 1 "This Regul~ http:~
## 2 1 General provi~ 1 Subject-matte~ 2 "This Regul~ http:~
## 3 1 General provi~ 1 Subject-matte~ 3 "The free m~ http:~
## 4 1 General provi~ 2 Material scope 1 "This Regul~ http:~
## 5 1 General provi~ 2 Material scope 2 "This Regul~ http:~
## 6 1 General provi~ 2 Material scope 3 "For the pr~ http:~
## 7 1 General provi~ 2 Material scope 4 "This Regul~ http:~
## 8 1 General provi~ 3 Territorial s~ 1 "This Regul~ http:~
## 9 1 General provi~ 3 Territorial s~ 2 "This Regul~ http:~
## 10 1 General provi~ 3 Territorial s~ 3 "the monito~ http:~
## # ... with 415 more rowsgdpr_violations## # A tibble: 250 x 11
## id picture name price authority date controller article_violated
## <dbl> <chr> <chr> <dbl> <chr> <date> <chr> <chr>
## 1 1 https:/~ Poland 9380 Polish N~ 2019-10-18 Polish Ma~ Art.28GDPR
## 2 2 https:/~ Roman~ 2500 Romanian~ 2019-10-17 UTTIS IND~ Art.12GDPR|Art.~
## 3 3 https:/~ Spain 60000 Spanish ~ 2019-10-16 Xfera Mov~ Art.5GDPR|Art.6~
## 4 4 https:/~ Spain 8000 Spanish ~ 2019-10-16 Iberdrola~ Art.31GDPR
## 5 5 https:/~ Roman~ 150000 Romanian~ 2019-10-09 Raiffeise~ Art.32GDPR
## 6 6 https:/~ Roman~ 20000 Romanian~ 2019-10-09 Vreau Cre~ Art.32GDPR|Art.~
## 7 7 https:/~ Greece 200000 Hellenic~ 2019-10-07 Telecommu~ Art.5(1)c)GDPR|~
## 8 8 https:/~ Greece 200000 Hellenic~ 2019-10-07 Telecommu~ Art.21(3)GDPR|A~
## 9 9 https:/~ Spain 30000 Spanish ~ 2019-10-01 Vueling A~ Art.5GDPR|Art.6~
## 10 10 https:/~ Roman~ 9000 Romanian~ 2019-09-26 Inteligo ~ Art.5(1)a)GDPR|~
## # ... with 240 more rows, and 3 more variables: type <chr>, source <chr>,
## # summary <chr>GDPR word counts
gdpr %>%
unnest_tokens(word, gdpr_text) %>%
anti_join(stop_words) %>%
filter(!str_detect(word, "[:digit:]")) %>%
count(chapter_title, word, chapter, sort = T) %>%
group_by(chapter_title) %>%
slice_max(n, n = 10) %>%
ungroup() %>%
mutate(word = reorder_within(word, n, chapter_title)) %>%
ggplot(aes(n, word, fill = factor(chapter))) +
geom_col() +
facet_wrap(~chapter_title, scales = "free") +
scale_y_reordered() +
labs(x = "# of words",
y = NULL,
fill = "chapter",
title = "Chapter-wise 10 most frequent words")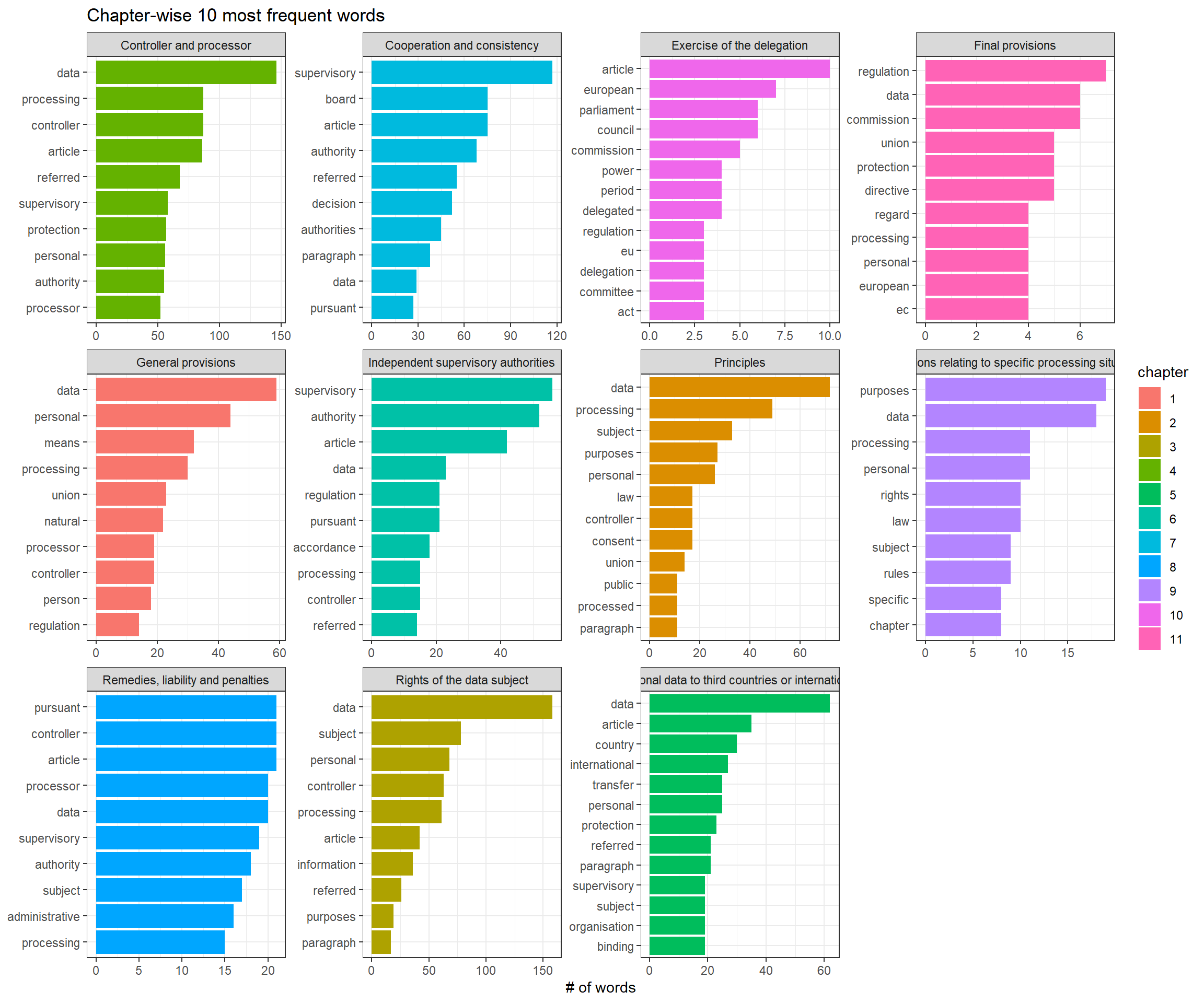
GDPR violations
gdpr_violations %>%
mutate(article_violated = str_remove_all(article_violated, " GDPR")) %>%
separate_rows(article_violated, sep = "\\|") %>%
mutate(article_violated = str_extract(article_violated, "Art\\.\\s?[:digit:]+")) %>%
count(name, article_violated, sort = T) %>%
filter(!is.na(article_violated)) %>%
mutate(article_violated = fct_reorder(article_violated, n, sum)) %>%
ggplot(aes(n, article_violated, fill = name)) +
geom_col() +
labs(x = "# of violations",
y = "violated article",
fill = NULL,
title = "Which articles have been violated most?")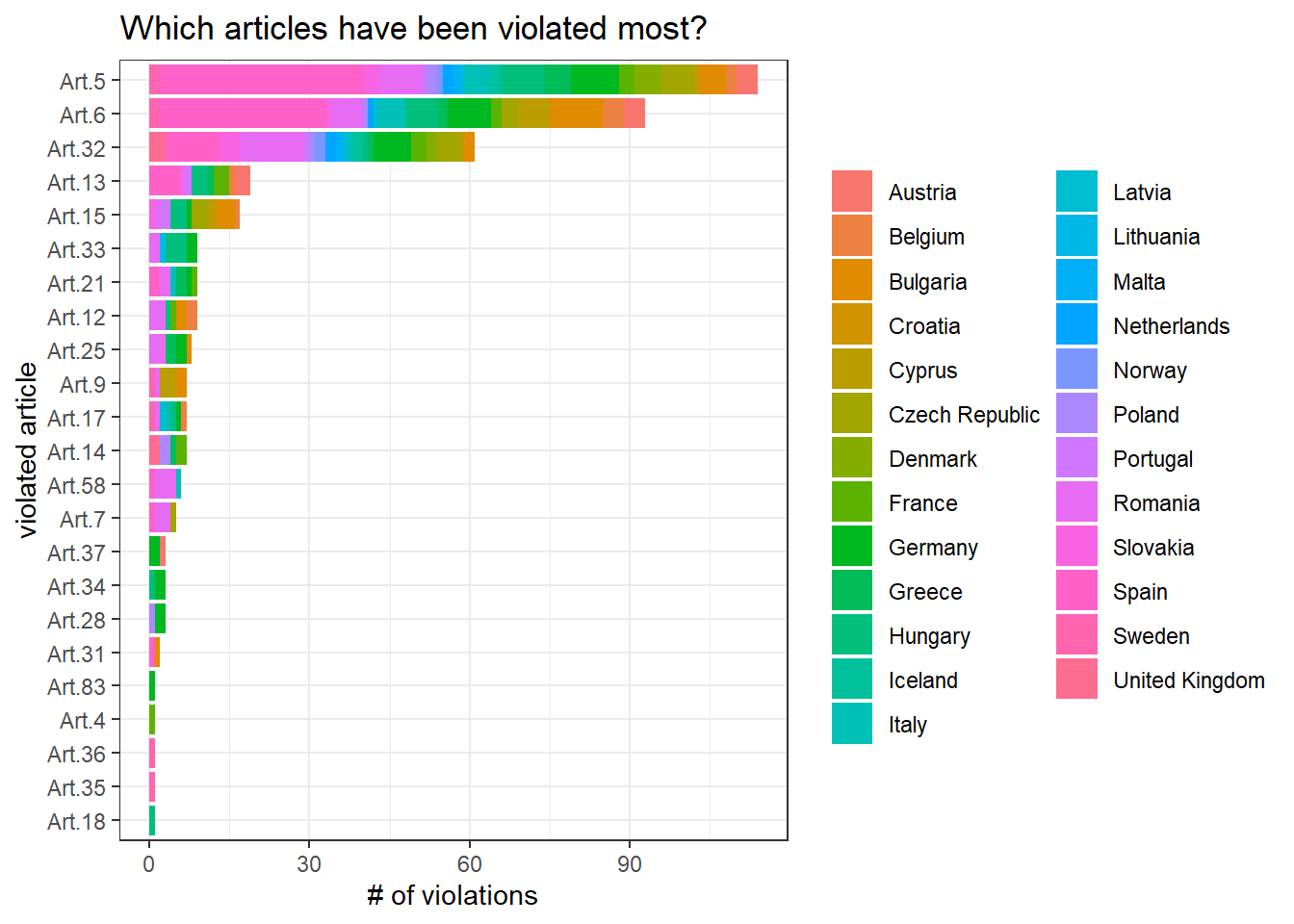
Fines
gdpr_violations %>%
mutate(article_violated = str_remove_all(article_violated, " GDPR")) %>%
separate_rows(article_violated, sep = "\\|") %>%
mutate(article_violated = str_extract(article_violated, "Art\\.\\s?[:digit:]+")) %>%
filter(!is.na(article_violated)) %>%
mutate(article_violated = fct_reorder(article_violated, price, median, na.rm = T)) %>%
ggplot(aes(price, article_violated, fill = article_violated)) +
geom_boxplot() +
scale_x_log10() +
theme(legend.position = "none") +
labs(x = "fine in Euros(€)",
y = "violated article",
title = "How much does article violation cost?") 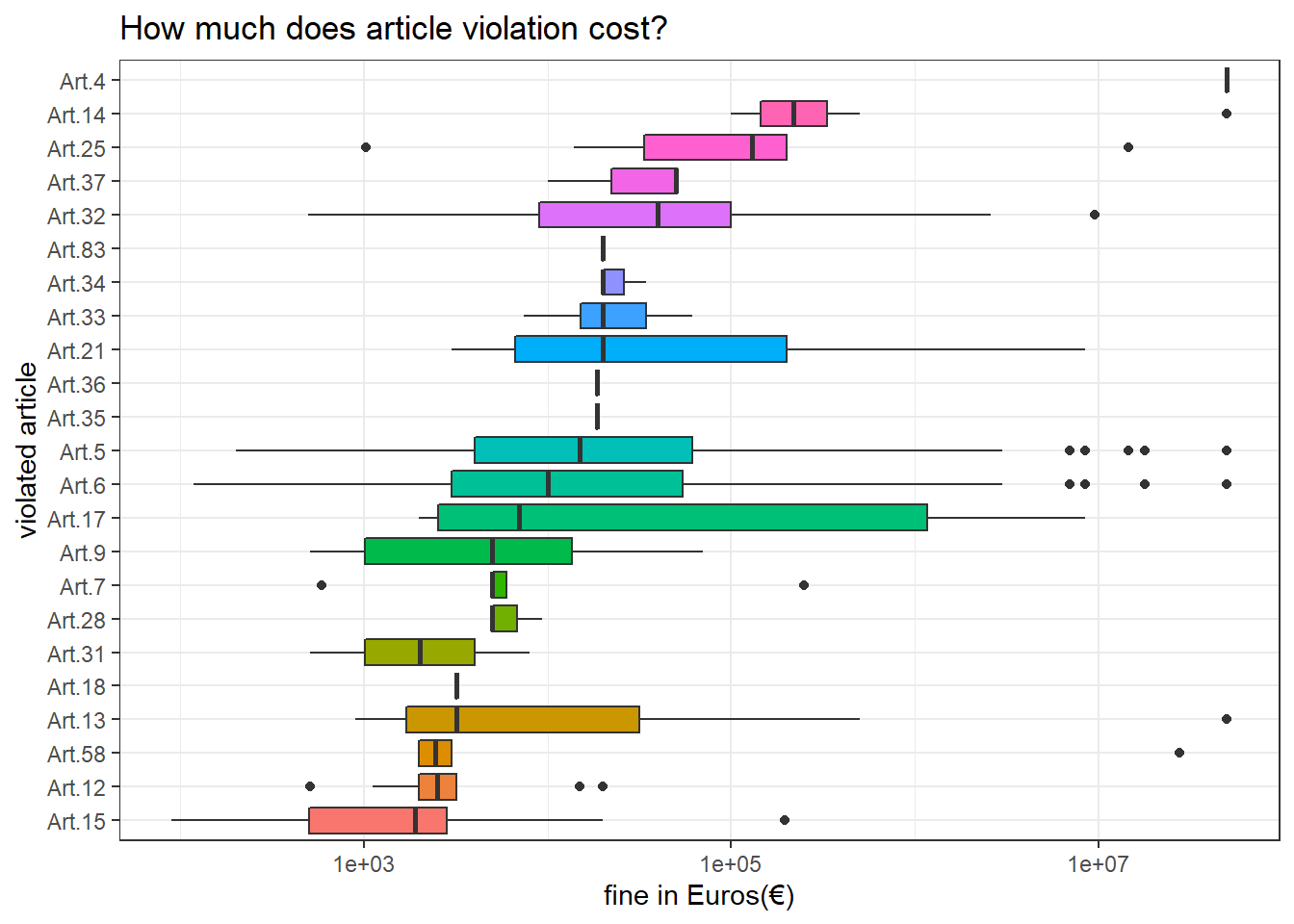
TF-IDF
gdpr_violations %>%
mutate(article_violated = str_remove_all(article_violated, " GDPR")) %>%
separate_rows(article_violated, sep = "\\|") %>%
mutate(article_violated = str_extract(article_violated, "Art\\.\\s?[:digit:]+")) %>%
filter(!is.na(article_violated)) %>%
unnest_tokens(word, type) %>%
anti_join(stop_words) %>%
count(article_violated, word, sort = T) %>%
bind_tf_idf(word, article_violated, n) %>%
group_by(article_violated) %>%
slice_max(tf_idf, n = 5) %>%
ungroup() %>%
mutate(article_violated = fct_reorder(article_violated, -tf_idf, sum),
word = reorder_within(word, tf_idf, article_violated)) %>%
ggplot(aes(tf_idf, word, fill = article_violated)) +
geom_col() +
scale_y_reordered() +
facet_wrap(~article_violated, scales = "free_y") +
theme(legend.position = "none") +
labs(x = "TF-IDF",
y = NULL,
title = "Top 5 words with the largest TF-IDF values")
Monthly average fine
gdpr_violations %>%
mutate(month = month(date, label = T)) %>%
group_by(name, month) %>%
summarize(avg_fine = mean(price)) %>%
ungroup() %>%
ggplot(aes(month, name, fill = avg_fine)) +
geom_tile() +
theme(panel.grid = element_blank()) +
scale_fill_gradient2(low = "green",
high = "red",
mid = "pink",
midpoint = 2e+07,
labels = dollar) +
labs(x = NULL,
y = NULL,
fill = "average fine",
title = "Average Fine Per Country Per Month") 
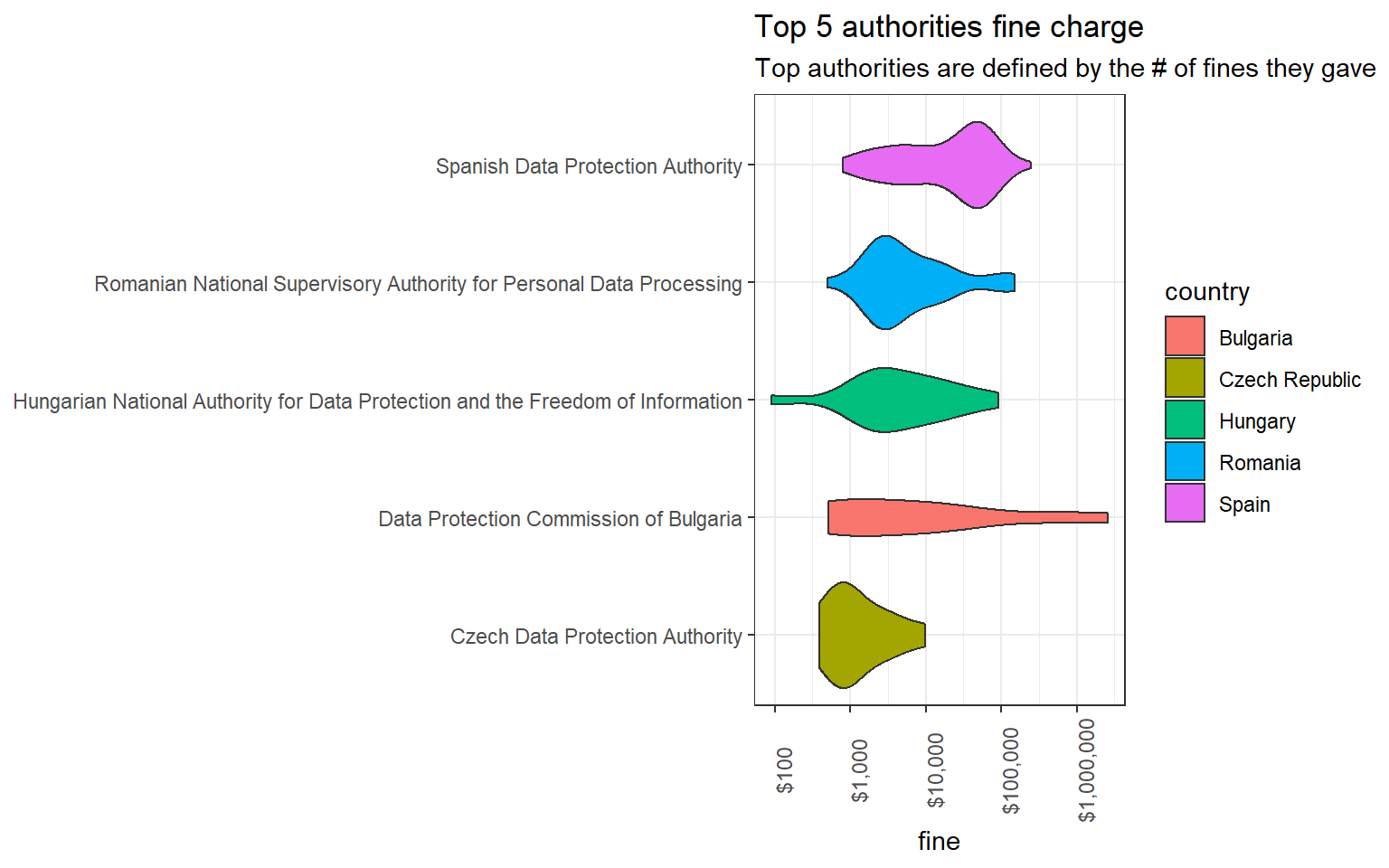
gdpr_violations %>%
mutate(authority = fct_lump(authority, 5),
authority = str_remove(authority, " \\(.+$")) %>%
filter(authority != "Other") %>%
ggplot(aes(price, authority, fill = name)) +
geom_violin() +
scale_x_log10(label = dollar) +
theme(axis.text.x = element_text(angle = 90)) +
labs(x = "fine",
y = NULL,
fill = "country",
title = "Top 5 authorities fine charge",
subtitle = "Top authorities are defined by the # of fines they gave")