Using LASSO to Predict Office IMDB Rating
Mon, May 9, 2022
2-minute read
In this blog post, I will use LASSO model to predict IMDB rating of the Office show. The data set is provided by the schrute package. Some ideas in this blog post are inspired by Julia Silge’s post (link).
library(tidyverse)
library(tidymodels)
library(textrecipes)
library(lubridate)
library(vip)
theme_set(theme_bw())office <- schrute::theoffice %>%
mutate(air_date = ymd(air_date)) %>%
select(-c(director, writer, text_w_direction))IMDB rating per episode:
office %>%
distinct(imdb_rating, total_votes, air_date) %>%
ggplot(aes(air_date, imdb_rating)) +
geom_line() +
geom_point(aes(size = total_votes)) +
labs(x = "air date",
y = "IMDB rating",
size = "total votes",
title = "The Office IMDB Rating per Episode and Total Votes")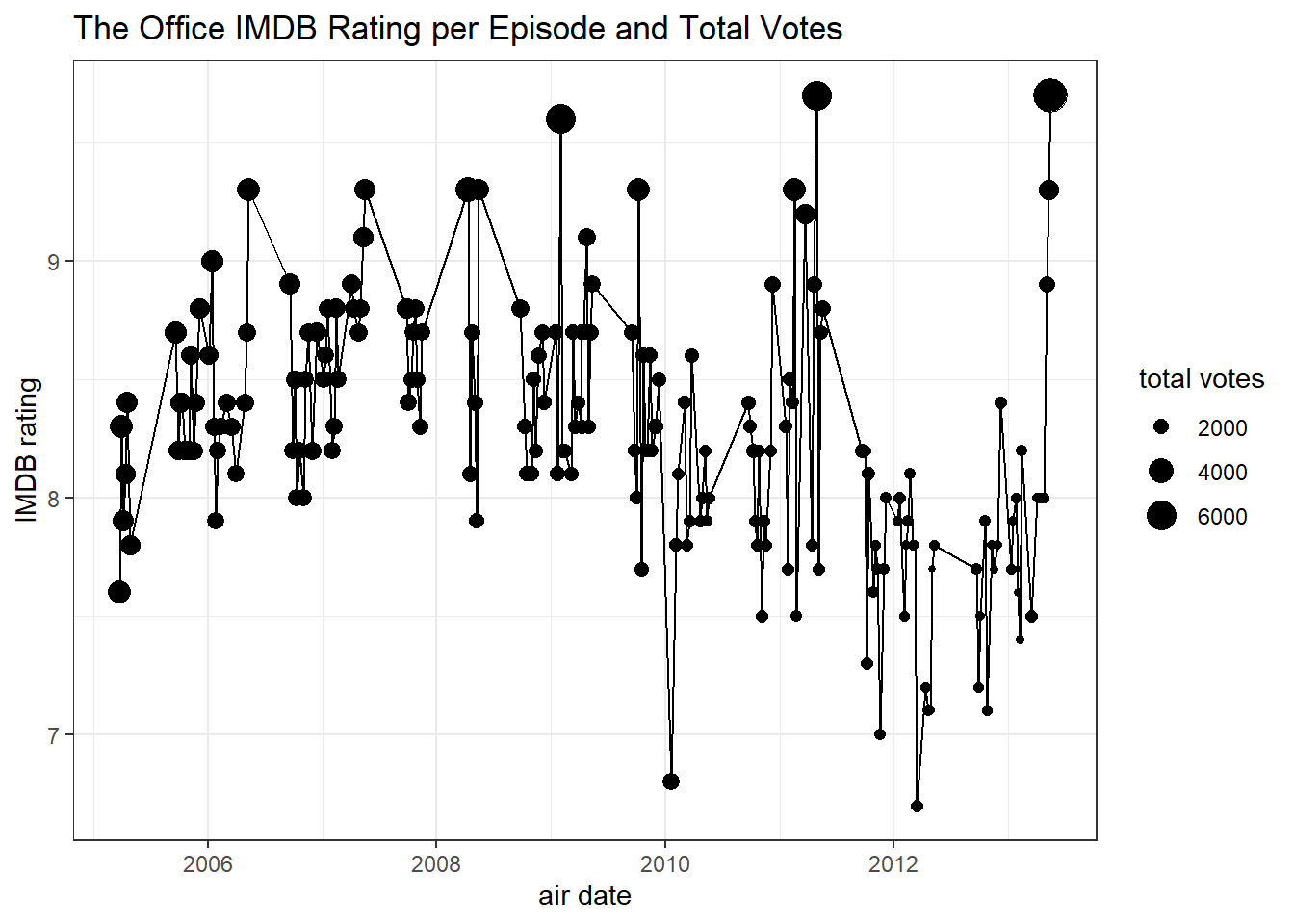
IMDB rating per season:
office %>%
mutate(season = factor(season)) %>%
ggplot(aes(season, imdb_rating, fill = season, color = season)) +
geom_boxplot(show.legend = F, alpha = 0.5) +
theme(panel.grid = element_blank()) +
labs(y = "IMDB rating",
title = "IMDB Rating per Season")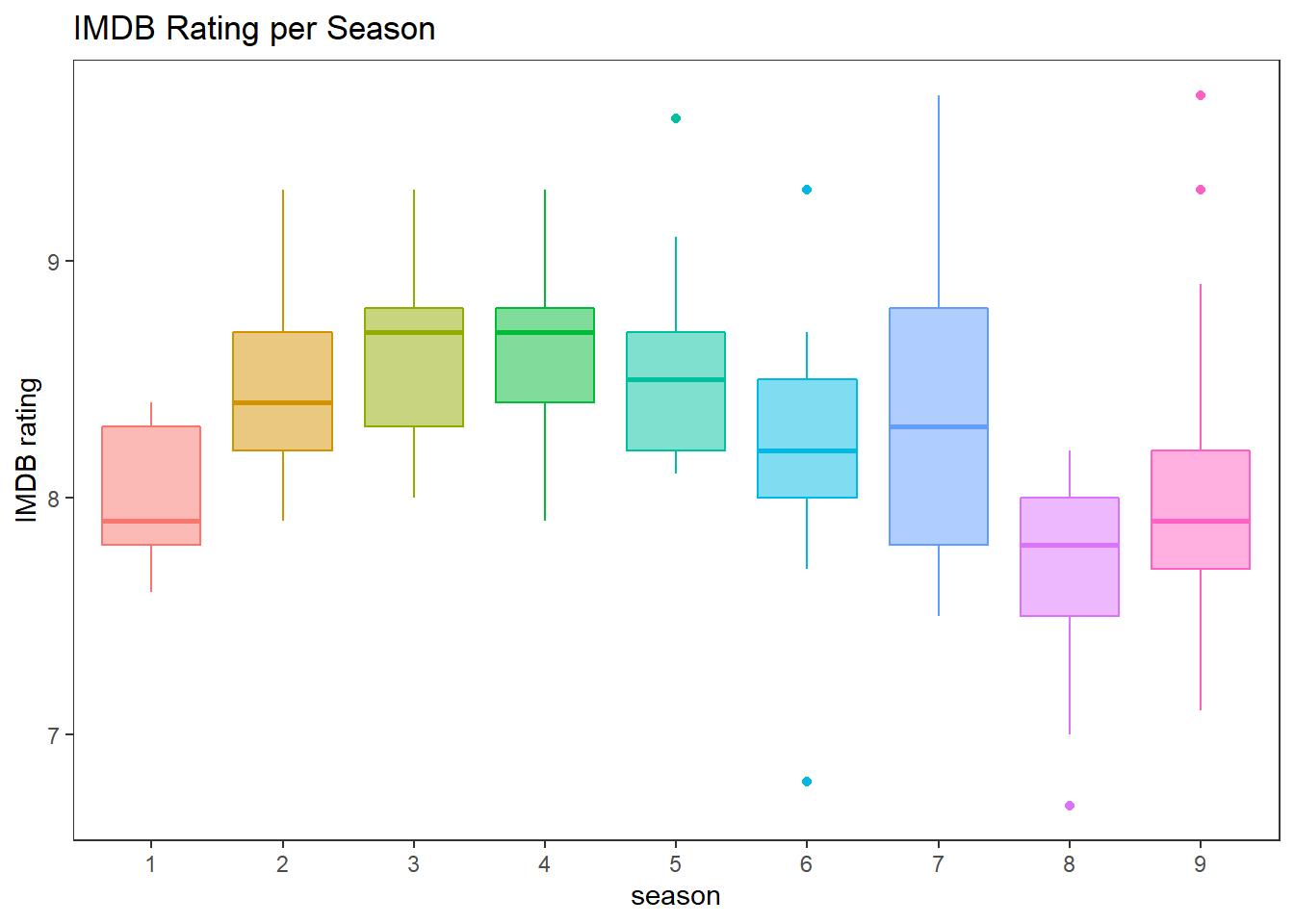
Top 10 Characters:
office %>%
filter(fct_lump(character, n = 10) != "Other") %>%
group_by(character) %>%
summarize(imdb_rating = mean(imdb_rating),
votes = mean(total_votes),
total_lines = n()) %>%
pivot_longer(2:4) %>%
ggplot(aes(character, value, fill = character)) +
geom_col(show.legend = F) +
facet_wrap(~name, ncol = 1, scales = "free_y") +
labs(title = "Top 10 Characters' Average Rating, Total Lines, and Votes")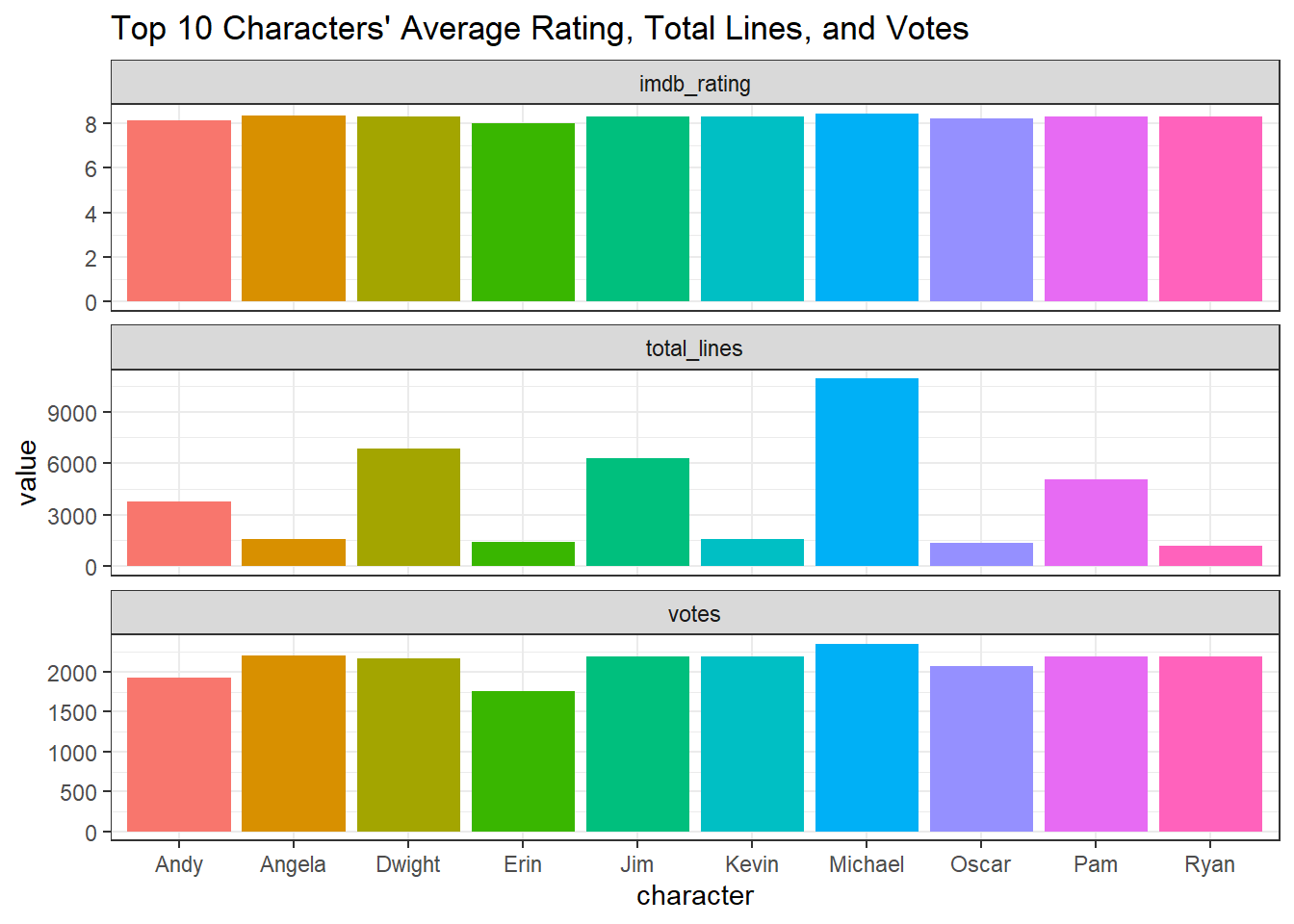
Now I’d like to use LASSO to predict the IMDB rating by using the tidymodels machine learning framework.
Split the data:
set.seed(2022)
office_spl <- office %>%
initial_split()
office_train <- training(office_spl)
office_test <- testing(office_spl)
office_folds <- vfold_cv(office_train, v = 5)Make a recipe:
imdb_rec <- recipe(imdb_rating ~ ., data = office_train) %>%
update_role(index, new_role = "id") %>%
update_role(episode_name, new_role = "id") %>%
step_other(character, threshold = 0.1) %>%
step_date(air_date, features = "year") %>%
step_rm(air_date) %>%
step_tokenize(text) %>%
step_stopwords(text) %>%
step_tokenfilter(text, max_times = 300) %>%
step_tf(text) %>%
step_dummy(all_nominal_predictors())Specify the LASSO model:
lasso_spec <- linear_reg(penalty = tune()) %>%
set_engine("glmnet") %>%
set_mode("regression")Set up the LASSO workflow:
lasso_wf <- workflow() %>%
add_recipe(imdb_rec) %>%
add_model(lasso_spec)Tune the LASSO model on the penalty parameter:
lasso_res <- lasso_wf %>%
tune_grid(
office_folds,
grid = crossing(penalty = 10 ^ seq(-7, -0.5, 0.5))
)
autoplot(lasso_res)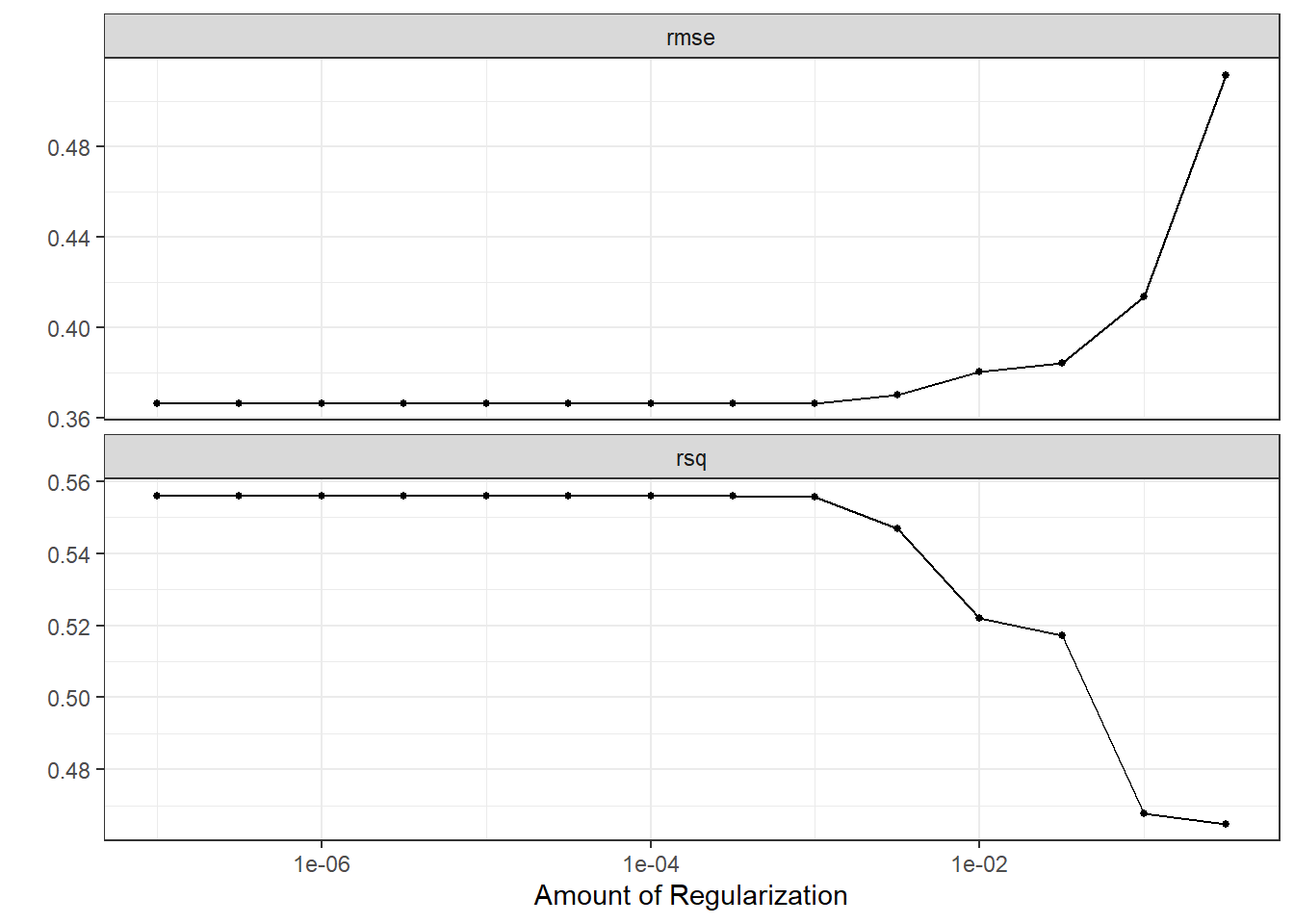
Fit the model on the training data and test it on the test data:
lasso_last_fit <- lasso_wf %>%
finalize_workflow(
lasso_res %>%
select_best("rmse")
) %>%
last_fit(office_spl)
lasso_last_fit %>%
collect_predictions() %>%
ggplot(aes(imdb_rating, .pred)) +
geom_point(alpha = 0.2, size = 1) +
geom_abline(lty = 2, color = "red", size = 2) +
labs(x = "IMDB rating",
y = "Predicated IMDB rating",
title = "Truth VS Predictions")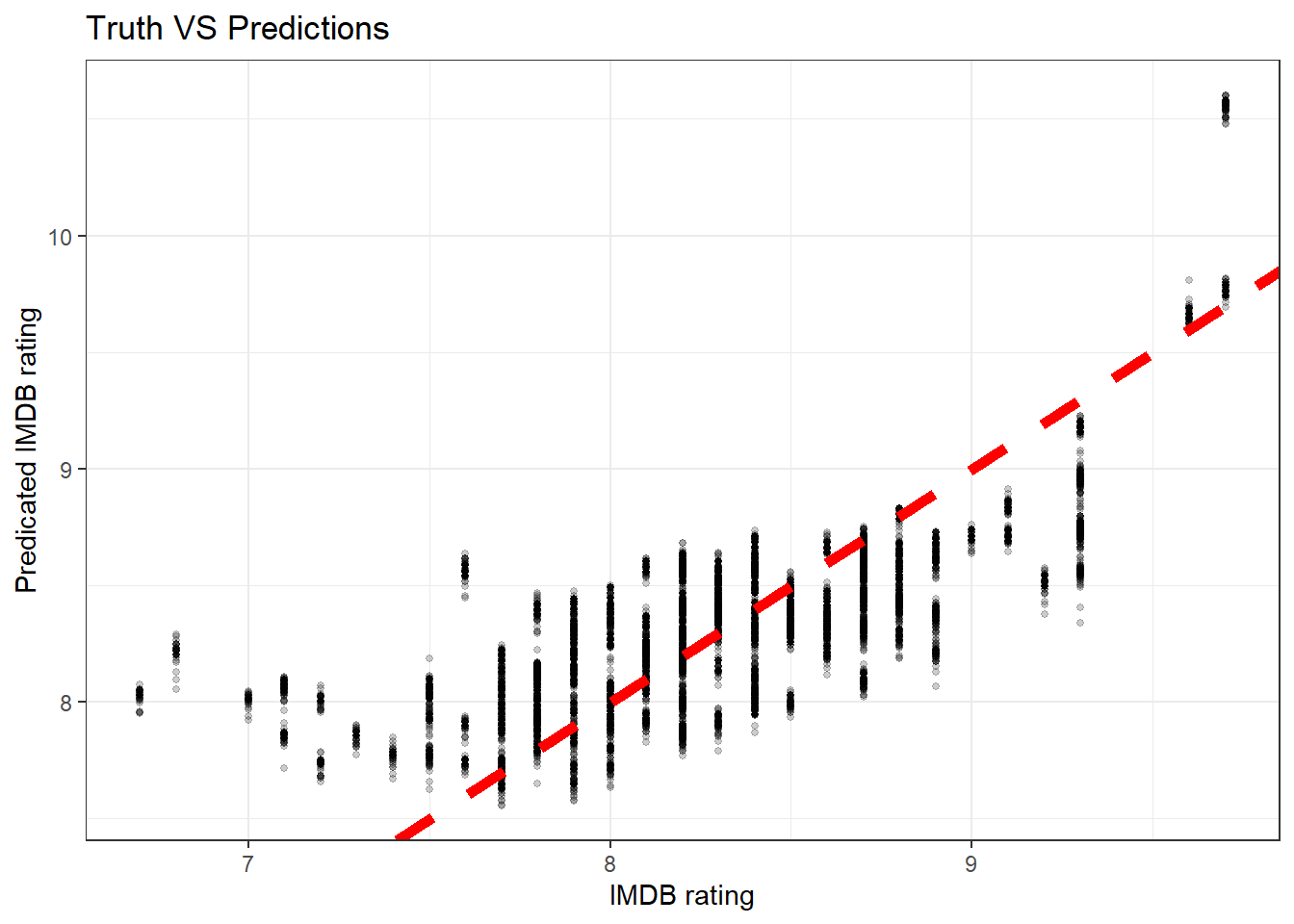
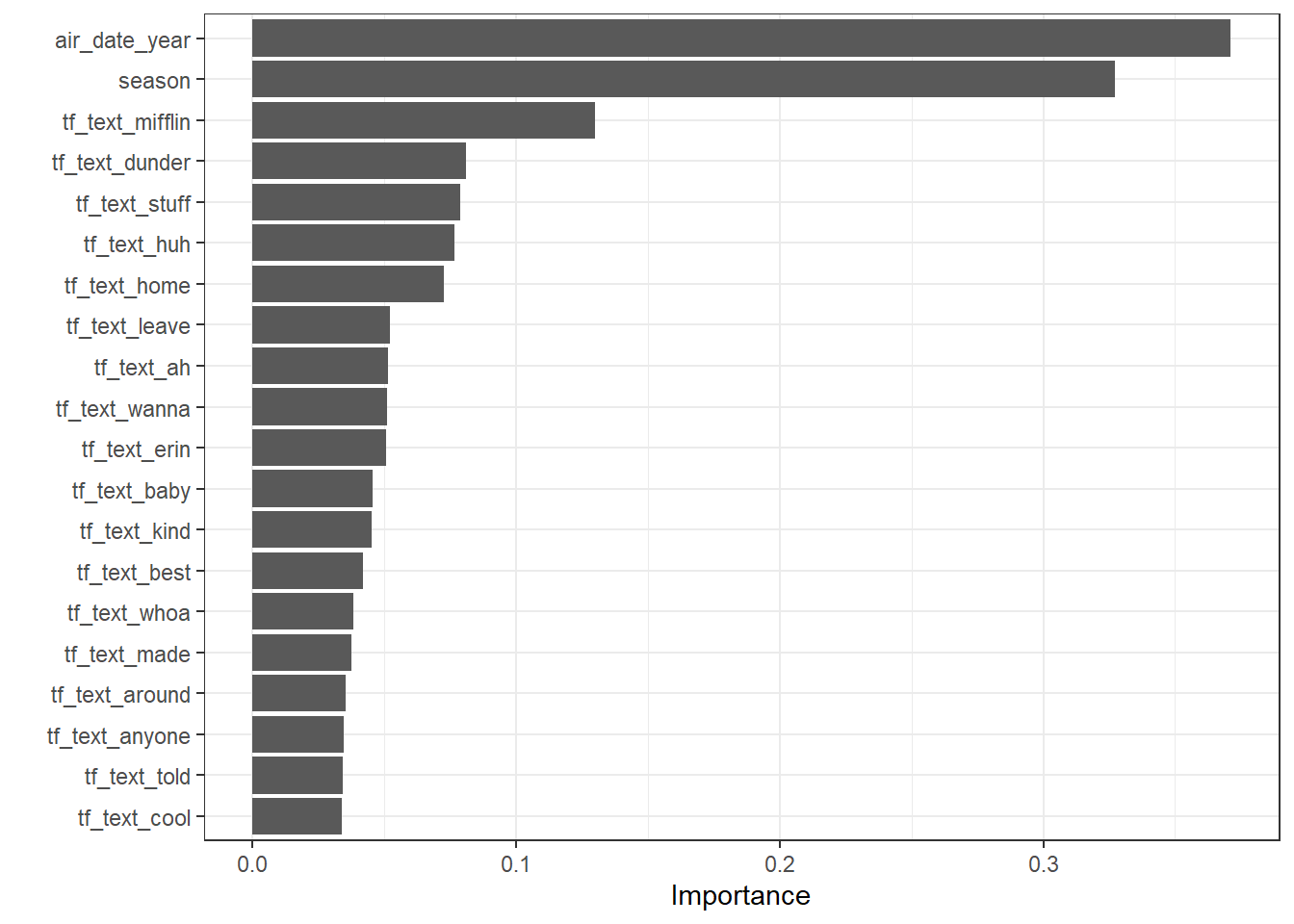
Variable Importance:
lasso_last_fit %>%
extract_fit_parsnip() %>%
vip(num_features = 20)