PCA on Cocktail Ingredients (with recipes package used)
Wed, May 25, 2022
3-minute read
In this blog post, I will use step_pca() provided by the recipe package to apply PCA analysis to a cocktail dataset. A similar blog post of mine, which you can view here, provides PCA analysis on the same dataset. The difference is that post uses svd() approach to carry out the analysis, but this post uses the tidymodels approach.
library(tidyverse)
library(tidymodels)
theme_set(theme_bw())boston_cocktails <- read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-05-26/boston_cocktails.csv") %>%
mutate(measure = str_remove(measure, " oz"))
boston_cocktails## # A tibble: 3,643 x 6
## name category row_id ingredient_numb~ ingredient measure
## <chr> <chr> <dbl> <dbl> <chr> <chr>
## 1 Gauguin Cocktail Classics 1 1 Light Rum 2
## 2 Gauguin Cocktail Classics 1 2 Passion F~ 1
## 3 Gauguin Cocktail Classics 1 3 Lemon Jui~ 1
## 4 Gauguin Cocktail Classics 1 4 Lime Juice 1
## 5 Fort Lauderdale Cocktail Classics 2 1 Light Rum 1 1/2
## 6 Fort Lauderdale Cocktail Classics 2 2 Sweet Ver~ 1/2
## 7 Fort Lauderdale Cocktail Classics 2 3 Juice of ~ 1/4
## 8 Fort Lauderdale Cocktail Classics 2 4 Juice of ~ 1/4
## 9 Apple Pie Cordials and Liqu~ 3 1 Apple sch~ 3
## 10 Apple Pie Cordials and Liqu~ 3 2 Cinnamon ~ 1
## # ... with 3,633 more rowsClean up boston_cocktails and widen it:
cocktail_wide <- boston_cocktails %>%
mutate(measure = str_replace(measure, "\\s?1/2", ".5"),
measure = str_replace(measure, "\\s?1/4", ".5"),
measure = str_replace(measure, "\\s?3/4", ".75"),
measure = str_replace(measure, "\\s?1/3", ".33"),
measure = str_replace(measure, "\\s?2/3", ".66"),
measure = str_replace(measure, "\\s.+$", "")) %>%
filter(!is.na(measure)) %>%
mutate(measure = as.numeric(measure)) %>%
distinct(row_id, ingredient, .keep_all = T) %>%
select(name, category, ingredient, measure) %>%
add_count(ingredient) %>%
filter(n > 15) %>%
select(-n) %>%
pivot_wider(names_from = "ingredient",
values_from = "measure",
values_fill = 0) %>%
janitor::clean_names()
cocktail_wide## # A tibble: 913 x 49
## name category light_rum lemon_juice sweet_vermouth juice_of_a_lime
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Gauguin Cocktai~ 2 1 0 0
## 2 Fort Lauderdale Cocktai~ 1.5 0 0.5 0.5
## 3 Cuban Cocktail~ Cocktai~ 2 0 0 0.5
## 4 Cool Carlos Cocktai~ 0 0 0 0
## 5 John Collins Whiskies 0 0 0 0
## 6 Cherry Rum Cocktai~ 1.5 0 0 0
## 7 Casa Blanca Cocktai~ 2 0 0 0
## 8 Caribbean Cham~ Cocktai~ 0.5 0 0 0
## 9 Amber Amour Cordial~ 0 0 0 0
## 10 The Joe Lewis Whiskies 0 0 0 0
## # ... with 903 more rows, and 43 more variables: powdered_sugar <dbl>,
## # dark_rum <dbl>, cranberry_juice <dbl>, pineapple_juice <dbl>,
## # bourbon_whiskey <dbl>, fresh_lemon_juice <dbl>, simple_syrup <dbl>,
## # cherry_flavored_brandy <dbl>, light_cream <dbl>, triple_sec <dbl>,
## # maraschino <dbl>, amaretto <dbl>, grenadine <dbl>, apple_brandy <dbl>,
## # brandy <dbl>, gin <dbl>, anisette <dbl>, orange_juice <dbl>,
## # dry_vermouth <dbl>, fresh_lime_juice <dbl>, orange_bitters <dbl>, ...The PCA recipe:
pca_prep <- recipe(~., data = cocktail_wide) %>%
update_role(name, category, new_role = "id") %>%
step_normalize(all_predictors()) %>%
step_pca(all_predictors()) %>%
prep()
pca_prep %>%
broom::tidy(2) %>%
filter(component %in% c("PC1", "PC2", "PC3", "PC4")) %>%
group_by(component) %>%
slice_max(value, n = 10, with_ties = F) %>%
ungroup() %>%
mutate(terms = str_replace_all(terms, "_", " "),
terms = fct_reorder(terms, value)) %>%
ggplot(aes(value, terms, fill = component)) +
geom_col() +
facet_wrap(~component, scales = "free_y") +
theme(legend.position = "none") 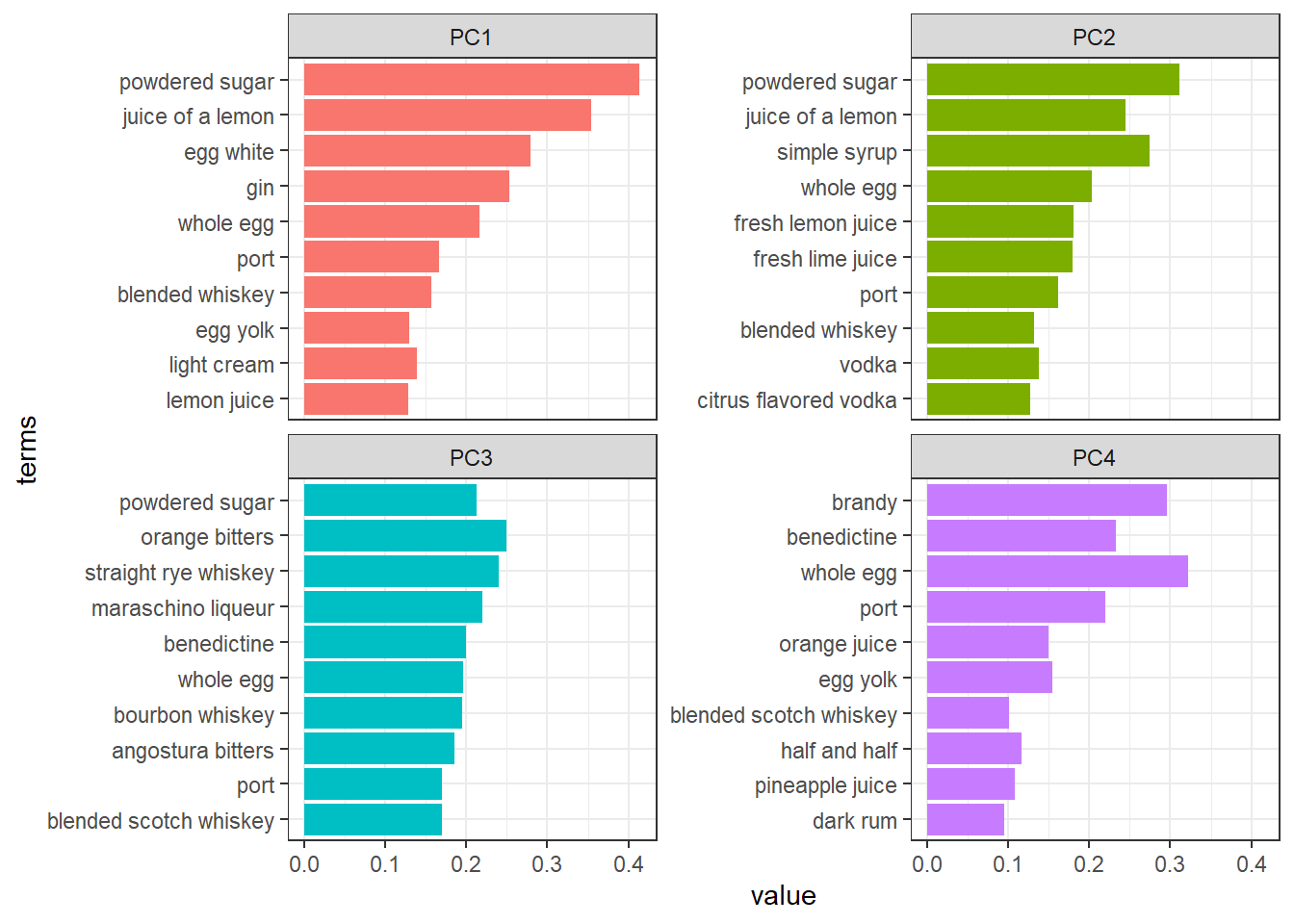
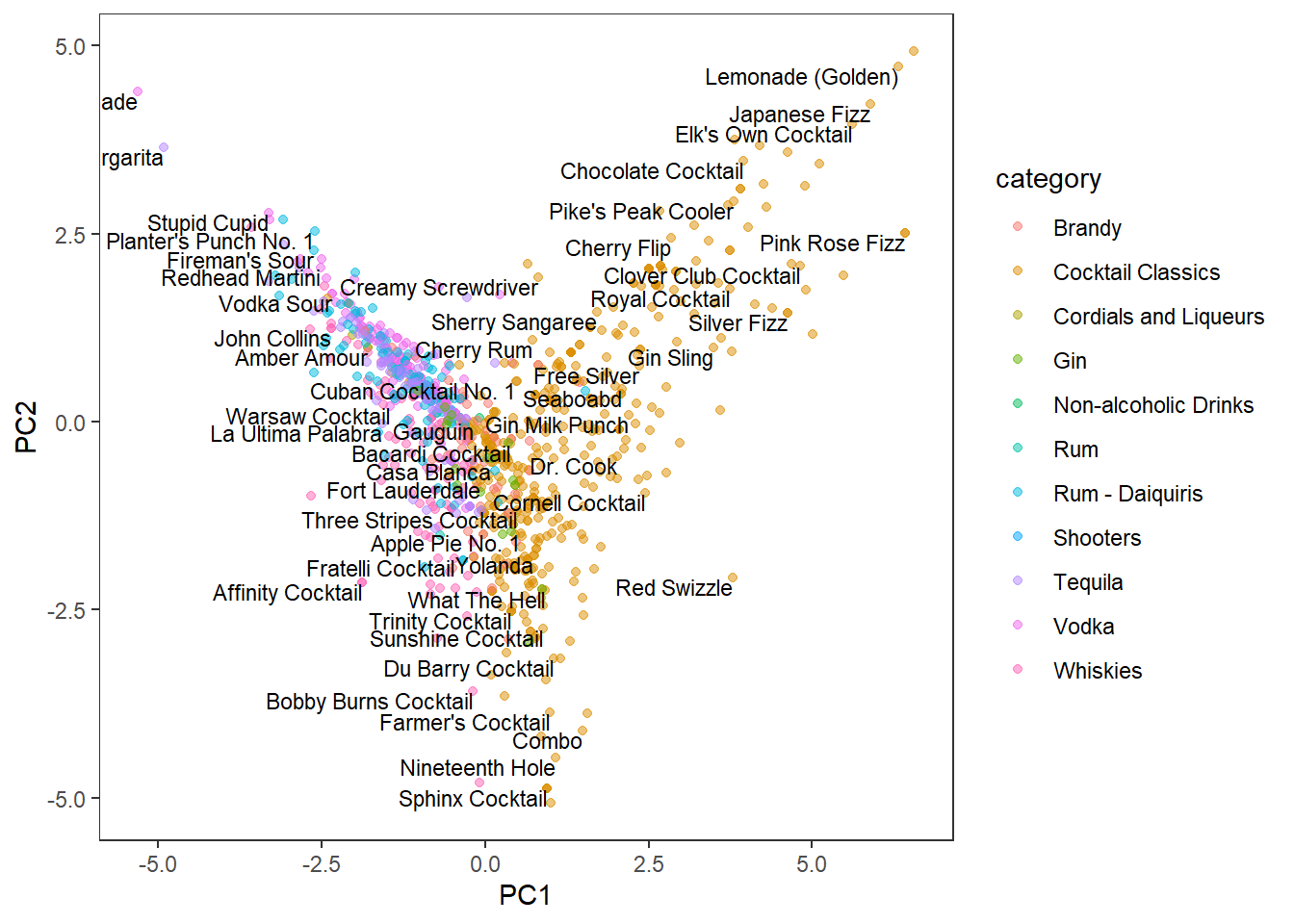
PC1 VS PC2:
bake(pca_prep, new_data = NULL) %>%
ggplot(aes(PC1, PC2)) +
geom_point(aes(color = category), alpha = 0.5) +
geom_text(aes(label = name),
size = 3,
hjust = 1,
vjust = 1,
check_overlap = T) +
theme(panel.grid = element_blank())